Guide to Safe AI Development
1. Safe Development of Artificial Intelligence Systems
1.1. Introduction
Artificial intelligence (AI) refers to information systems or devices capable of performing functions considered intelligent, such as:
- Speech recognition
- Image recognition
- Recommendation engines
- Automated decision-making systems
Most modern AI systems are built using machine learning, where the system learns patterns and behavior from data.
Safe development requires that:
- Data processing is secure and lawful
- Systems ensure the protection of citizens' fundamental rights
- AI systems do not pose physical or psychological risks to health or well-being.
1.2. Requirements for a Secure AI System
| Requirement | Description / Instructions |
|---|---|
| Information Security and Data Protection | Ensure confidentiality, integrity, and availability. Data access must be restricted to authorized users. Organizations must comply with data protection regulations, including privacy legislation such as GDPR or equivalent frameworks. |
| Safty for Users and Society | Systems must not pose risks to people, especially in critical infrastructure such as transportation. Quality assurance processes must be implemented. |
| Protection of Fundamental Rights | AI systems must treat all citizens lawfully and fairly without violating individual rights. |
| Ethical Sustainability | Aim for long-term positive societal impacts. Ethical principles must be considered throughout the entire lifecycle of the system. |
1.3. Organizational Readiness for AI Projects
Organizations need several capabilities to develop AI safely. Key competencies include:
AI Expertise
Organizations must ensure that employees understand:
- Basic AI concepts
- Data-driven decision-making
- Machine learning principles
AI literacy should extend beyond technical teams to include management and policy stakeholders.
Data Platforms and Integration
AI relies heavily on data management, such as:
- Databases
- Data warehouses
- Data lakes
- Integration systems
Software Development
AI systems are still software systems. Organizations must maintain strong engineering practices such as:
- Version control
- Quality management
- Continuous integration and deployment
- Quality assurance
Legal Expertise
Organizations must understand the legal implications of AI systems, particularly regarding:
- Data protection laws
- AI regulation
- Automated decision-making legislation
Ethical Expertise
Organizations should define ethical guidelines for AI and data use.
1.4. AI, Machine Learning, and Common Challenges
Most AI systems rely on machine learning models trained on data. Different learning approaches exist, each with strengths and risks.
| Learning Format | Principle | Security / Safety Challenge |
|---|---|---|
| Supervised Learning | Model learns from labeled examples (input-output pairs). | Training data may contain hidden biases or discrimination. |
| Unsupervised Learning | Model identifies patterns or clusters without labels. | Results can be difficult to interpret or may rely on incomplete data. |
| Reinforcement Learning | Model learns through trial and error using rewards and penalties. | Designing safe reward systems is difficult and may lead to unsafe behavior. |
2. Defining AI Solutions
The definition phase is the most critical stage of an AI project. It helps identify legal, ethical, and technical boundaries before implementation begins.
2.1. Legal Considerations
AI systems often process sensitive data. Developers must ensure compliance with relevant laws governing:
- Personal data protection
- Automated decision-making
- AI system regulation
During the design phase, organizations should document:
- Data sources used
- Personal data involved
- Legal justification for data usage
- Data lifecycle management
- Consent requirements
If personal data is processed, a data protection impact assessment (DPIA) may be required.
2.2. Ethical Considerations
Legal compliance alone is not sufficient for responsible AI. Organizations must also evaluate ethical implications.
Key ethical principles include:
- Respect for human autonomy
- Prevention of harm
- Fairness and non-discrimination
- Transparency
- Accountability
AI systems should also promote:
- Social well-being
- Environmental sustainability
- Inclusive digital services
2.3. Technical Boundary Conditions
Organizations must define their technical architecture and responsibilities.
-
Off-the-shelf Products: Clarify responsibility between the vendor and the organization.
-
Pre-trained Models: Acknowledge the limited ability to modify the base logic and plan for error correction.
-
Cloud vs. On-Premise Infrastructure: Define
- Where data is stored
- Whether data is transferred outside the Cambodia
- Security and compliance requirements
3. Data Collection and Processing
When processing data materials containing personal data, it is essential to be familiar with the following key concepts:
-
Anonymization: the removal of direct identifiers of personal data (name, social security number, address, etc.) encryption in such a way that the identity of the data subject cannot be restored afterwards with reasonable resources.
-
Pseudonymization: the concealment of direct identifiers (name, personal identification number, address, etc.) of personal data so that the identity of the data subject is not revealed. However, the identity can be restored afterwards.
Data Usage Levels in AI Systems
| Data Usage Level | Purpose | Impact on Individuals | Type of Data Used | Example Use Cases | Key Safeguards |
|---|---|---|---|---|---|
| Strategic | Analyze trends and support long-term planning or policy decisions | Low – does not directly affect individuals | Aggregated or anonymized data | Policy analysis, population statistics, market trends, performance analytics | Use anonymized datasets, remove personal identifiers, restrict analyst access |
| Tactical | Improve internal processes and operational efficiency | Medium – may use personal data but does not directly decide for individuals | Operational datasets, often pseudonymized | Document classification, workflow automation, customer support routing, fraud alerts | Apply pseudonymization, enforce access controls, limit data scope, monitor outputs |
| Operational | Make or support decisions affecting individual users | High – directly impacts individuals | Personal and transactional data | Loan approval, identity verification, personalized services, healthcare diagnosis | Ensure data accuracy, enable human oversight, ensure transparency, prevent discrimination |
4. Training AI Model
Training an AI model follows a structured process to ensure that the model performs reliably, fairly, and securely. The development process typically includes several iterative stages.
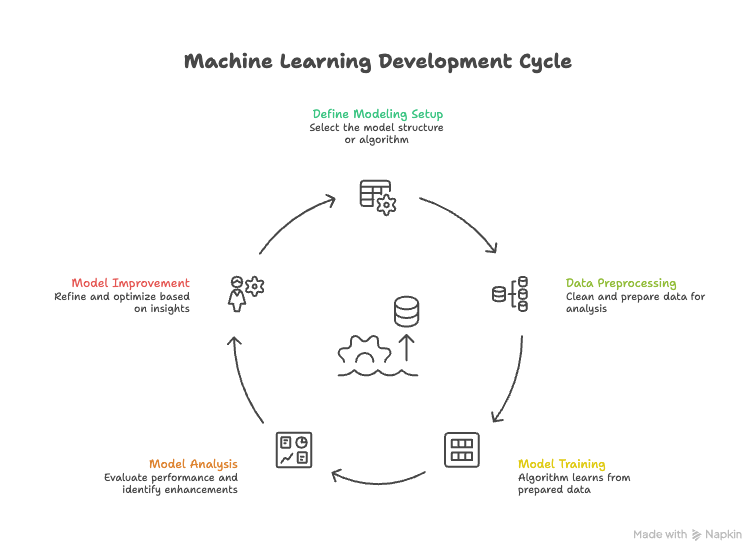
4.1. Defining the Modeling Setup
The first step is to define the modeling approach.
Key tasks include:
- Selecting the model structure or algorithm
- Choosing the variables used in the model
- Defining the prediction target
- Ensuring that discriminatory variables are not used as input
Examples of discriminatory variables that should not be used include: Age, Gender, Language, Religion or Nationality.
Variables that indirectly represent these characteristics must also be avoided.
4.2. Data Preprocessing
Before training, the dataset must be prepared and cleaned.
Typical preprocessing steps include:
- Data cleaning
- Feature selection
- Data normalization
- Handling missing values
The dataset must be split into:
- Training dataset
- Validation dataset
- Test dataset
Normalization should be performed separately for each dataset to avoid data leakage.
Additionally:
- Datasets must be version controlled
- Personal data must be anonymized or pseudonymized
If personal data is used, techniques such as differential privacy may be applied to protect individuals.
4.3. Model Training
In this stage, the AI model is trained using the prepared data.
Key practices include:
- Training one or more models
- Adjusting model parameters
- Evaluating learning performance during training
The training process may need to be repeated several times until the model achieves acceptable performance.
Models should also be stored with version control to enable traceability and reproducibility.
4.4. Model Analysis
After training, the model must be evaluated.
Evaluation includes:
- Measuring prediction accuracy
- Assessing fairness metrics
- Checking for bias or discrimination
- Evaluating model reliability
This analysis helps determine whether the model performs correctly across different groups and scenarios.
4.5. Model Improvement and Iteration
If the model does not meet expectations, improvements are required.
Possible improvement actions include:
- Adjusting the model architecture
- Modifying preprocessing methods
- Adding or removing variables
- Correcting data biases
Model development is typically iterative, meaning the training process may be repeated multiple times until the model performs as intended.
5. Deployment and Security Threats
When deploying an AI solution into production, the focus shifts from development to continuous monitoring, maintenance, and improvement of the model. Organizations must ensure that the model operates reliably and that any changes are carefully controlled.
| Scenario | Developer Guidelines |
|---|---|
| Model is used in new situations not seen during training | - Expand training data to include new real-world scenarios. - Add new test cases that define expected behavior. - Retrain or update the model to better represent real-world cases. |
| Model update causes previously working features to break | - Implement mechanisms to detect behavior changes during development. - Increase regression test coverage. - Ensure existing functionality continues to work when new features are added. |
| Fairness metrics change after model update | - Continuously monitor fairness metrics. - Detect changes in fairness across groups. - Correct the model before releasing updates. |
| Model explainability or behavior changes unexpectedly | - Monitor changes in model explainability. - Detect undesirable changes in model behavior. - Adjust or retrain the model when necessary. |
| New biases appear in training data or predictions | - Continuously monitor datasets and predictions for bias. - Correct bias before deploying updated models. |
| Model input variables change and include discriminatory attributes | - Detect changes in input variables and model structure early. - Remove discriminatory variables or variables strongly correlated with them before release. |
| Model behavior influences users in a way that reinforces social bias | - Evaluate whether the model reinforces societal biases. - Assess potential feedback loops or negative spiral effects. |
| Model, training data, or variables are modified without documentation | - Maintain version control for models and training data. - Document all changes to models and datasets. - Ensure changes are traceable across versions. |
| System uses third-party AI models that change over time | - Monitor behavior changes in external models or components. - Use automated tests to detect deviations from expected behavior. |
| Security vulnerabilities appear in software libraries | - Regularly monitor dependencies for vulnerabilities. - Apply security patches promptly. - Use tools that detect programming errors and dependency risks early. |
Security Risks in Artificial Intelligence Systems
Artificial intelligence systems are complex software systems that rely on data, models, and supporting infrastructure. As a result, they are exposed to various security risks throughout their lifecycle, including during model training, deployment, and operation. These risks may target sensitive training data, model parameters, system inputs, or the supporting software environment. If exploited, such vulnerabilities may lead to data leakage, model manipulation, degraded performance, or unauthorized access to AI capabilities.
To ensure the reliability, security, and integrity of AI systems, organizations must identify potential threats and implement appropriate safeguards. The following table outlines common threats to AI systems and recommended protection measures to mitigate these risks.
| Threat | How to Protect the System |
|---|---|
| AI model leakage or theft | - Restrict access to the trained model so only authorized users can access it. - Prevent attackers from reconstructing the model using input–output queries by limiting the number of requests to the model. - Use distributed or decentralized training so that leaking one part of the model does not expose the entire system. |
| Training data leakage | - Protect training data with proper access controls. - Secure communication channels used to transfer data. - Use differential privacy techniques to add noise to the data and protect individual records. |
| Model reverse engineering from training data or examples | - Prevent exposure of training datasets. - Limit the number of queries allowed to the model to reduce the risk of reverse engineering. |
| Model evasion (manipulating inputs to fool the AI) | - Use adversarial training with modified examples to improve the model’s resistance to manipulation. - Monitor system inputs and predictions for unusual patterns that may indicate malicious input. |
| Training data poisoning | - Use techniques such as regularization and simpler model architectures to reduce sensitivity to malicious training data. - Apply differential privacy methods to reduce reliance on individual training inputs. |
| Manipulation of observation or input data | - Implement validation and controls to ensure that system inputs cannot be manipulated. |
| Denial or delay of model usage (service disruption) | - Enable local decision-making on user devices when appropriate to reduce dependence on central systems. - Continuously monitor system activity to detect denial-of-service attacks. |
| Blocking or interfering with sensor data | - Ensure the system can continue operating safely even if some sensors fail or cannot collect data. |
6. AI as a Productivity Tool (Generative AI)
Artificial intelligence (AI) acts as an everyday professional assistant, helping you write code, analyze text, create images, and translate languages. Due to the rapid rise of GenAI tools like ChatGPT, organizations should create clear rules to govern how these technologies are used in the workplace.
While these tools can improve productivity and creativity, they also present risks. For example, user inputs may contain confidential information, and outputs generated by AI may contain errors, biased content, or copyrighted material. Therefore, users must be cautious about the information they provide to AI systems and must verify the accuracy of AI-generated outputs.
When using AI tools for these tasks, organizations should ensure that confidential data is not shared, AI-generated content is carefully reviewed, and potential legal or copyright issues are considered. Human oversight remains essential to ensure the reliability and responsible use of AI-generated results.